LLM model self-attention
LLM 與 BERT 的核心運作差異:
從 Masking 到文字接龍與 BERT 的雙向編碼器(Encoder-only)架構不同,主流 LLM(如 GPT、Llama)採用的是 Decoder-only 架構。其核心差異在於 注意力機制(Self-Attention) 引入了 Causal Masking(因果遮罩):
空間上的限制(Masking): 在進行 $Q \times K^T$ 的矩陣運算後、進入 Softmax 前,模型會強行將「未來」位置的權重設為 $-\infty$。這使得輸入內容在運算時,每個詞語只能「看到」上文與自身,無法存取下文資訊。這種單向注意力確保了模型在處理當前 Token 時,不會提前「偷看」到後面的答案。
時間上的循環(Autoregressive): LLM 具備 自回歸(Auto-regressive) 機制。模型在每一輪輸入跑完數十層(如 96 層)Transformer 後,會透過最後的線性層對字典進行「投票」,預測出下一個機率最高的字。
文字接龍的本質: 生成新字後,模型會將該輸出與上一輪的結果合併,作為「新一輪」的完整輸入再次丟進 Transformer。這種「產出、回填、再輸入」的遞迴過程,正是 LLM 被形象化地稱為 「超級文字接龍」 的根本原因。
預訓練 Pretrain
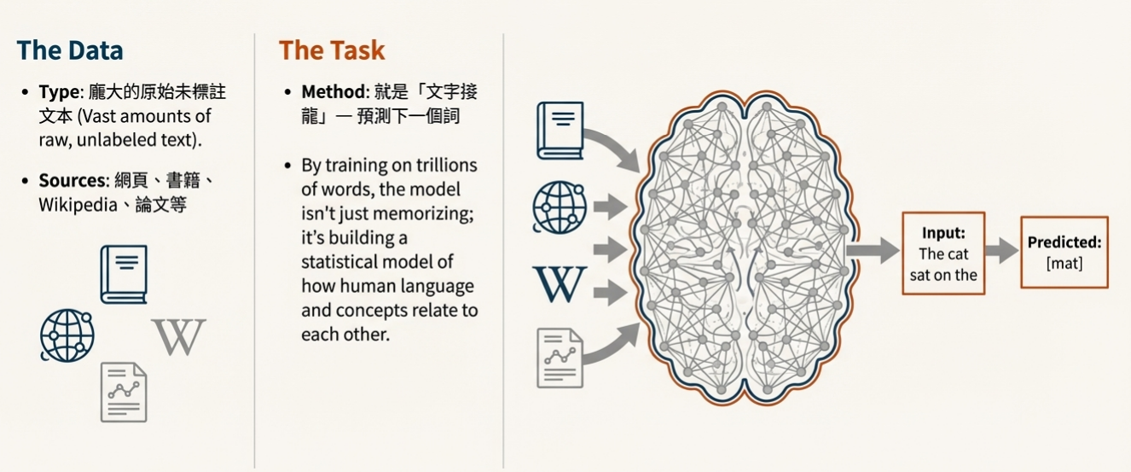
透過大量文本去訓練模型,讓模型學到通用的語法、語意與世界知識 (0 -> 1)
微調 Fintune
把模型的通用知識,發展成符合人類期望或是特定任務的能力 (1 -> …)